
پیشتر در مقاله “هوش مصنوعی (Artificial Intelligence): ماشینهایی که یاد میگیرند” اشاره کردم، یادگیری ماشین شاخهای از هوش مصنوعی است که در آن هدف استدلال کردن و تصمیمگیری بر اساس حجم زیادی از دادههای ورودی است. برای مثال، میتوان یک الگوریتم یادگیری ماشین را بهگونهای آموزش داد تا دادههای سلامتی و پزشکی یک بیمار مبتلا به غده سرطانی را دریافت و پیشبینی کند که غده سرطانی او خوشخیم است یا بدخیم.
نمونههای زیر همگی کاربردهایی از یادگیری ماشین هستند:
پیشبینی سطح دستمزد افراد بر اساس میزان تجربه کاری، سطح تحصیلات، رشته تحصیلی و …
پیشبینی اینکه قیمت سهام در روز بعد بالا خواهد رفت یا پایین،
تقسیمبندی مشتریان سازمان که دارای رفتار خرید مشابهی هستند،
پیشبینی اینکه آیا متقاضی وام یک بانک، میتواند در آینده بهطور کامل وام را بازپرداخت کند یا نمیتواند،
تشخیص اینکه ایمیل جدیدی که به صندوق پست الکترونیکی شما آمده، سالم است یا حاوی محتوای تبلیغاتی زرد (Spam)،
پیشبینی قیمت خودروهای دستدوم بر اساس کارکرد، مدل خودرو، عمر خودرو و …
اما یک ماشین چطور یاد میگیرد؟ پاسخ این است که همانطور که انسان یاد میگیرد. مثال پیشبینی قیمت خودروهای دستدوم را در نظر بگیرید. یک واسطهگر خودرو تازهکار، بهتدریج با دیدن نمونههای مختلف ماشین و قیمتهای معاملاتی متوجه میشود که چه عواملی بر روی قیمت تعیینکننده است. مثلاً ممکن است بهتدریج متوجه شود یک رنگ خاص در بازار طرفدار زیادی دارد، یا فلان مدل خودرو با قیمتهای بالاتری به فروش میرود. در ابتدای کارش ممکن است تخمینهایش از قیمت فروش اشتباه باشد ولی بهتدریج با دیدن نمونههای زیاد به یک درک شهودی از عوامل مختلف تأثیرگذار بر قیمت و شدت اثر آنان میرسد.
به زبان یادگیری ماشین، در مثال بالا، هر یک از عوامل تأثیرگذار بر قیمت، ویژگی (Feature) و یا متغیر پیشبینی کننده (Predictor Variable) نام دارند. در مثال پیشبینی خودروهای دستدوم، عمر خودرو، کیلومتر کارکرد، رنگ، مدل و … ویژگیهایی هستند که الگوریتم یادگیری ماشین از آنها استفاده میکند، تا قیمت خودرو را پیشبینی کند. به قیمت خودرو، متغیر پاسخ (Response Variable) یا هدف (Target Variable) گفته میشود.
یادگیرنده (Learner)، تلاش میکند تابعی را بهینه کند که ترکیبی از ویژگیها را پیدا کرده تا مقدار پیشبینی به مقدار واقعی متغیر پاسخ نزدیک شود. یادگیرندهها همان الگوریتمهای ریاضی هستند که موضوع اصلی در یادگیری ماشین هستند.
الگوریتمهای یادگیری ماشین را میتوان به سه دسته کلی تقسیم کرد:
یادگیری نظارتشده (Supervised Learning)،
یادگیری نظارتنشده (Unsupervised Learning) و
یادگیری تقویتی (Reinforcement Learning).
یادگیری نظارتشده
در یادگیری نظارتشده، هدف اصلی پیشبینی (Prediction) است. یادگیرنده به دنبال آن است تا الگویی کشف کند که با استفاده از ویژگیها متغیر پاسخ را پیشبینی کند. برای نمونه پیشبینی قیمت خودروهای دستدوم بر اساس کارکرد، مدل خودرو، عمر خودرو و … نمونهای از کاربرد یادگیری نظارتشده است.
در الگوریتمهای نظارتشده دادههای آموزش هم شامل متغیرهای پیشبینی کننده و هم شامل متغیر پاسخ است. علت آنکه به چنین الگوریتمهایی “نظارتشده” گفته میشود این است که فرآیند آموزش تحت نظر متغیر پاسخ صورت میگیرد. بهعبارتدیگر یادگیرنده تلاش میکند تا خود را به مقدار واقعی متغیر پاسخ نزدیک کند.
در فرآیند یادگیری، کل دادهها شامل متغیرهای پیشبینی کننده و متغیر پاسخ وارد الگوریتم میشوند. یادگیری در بیشتر الگوریتمهای یادگیری نظارتشده به معنی حل یک مسئله بهینهسازی (Optimization) با هدف کمینه کردن خطای پیشبینی مدل است.
مسائل یادگیری نظارتشده به دو حوزه اصلی تقسیم میشوند: مسائل رگرسیون (Regression) و مسائل دستهبندی (Classification).
وقتی هدف از مسئله نظارتشده، پیشبینی یک متغیر پیوسته (Continuous Variable) باشد، مسئله از نوع رگرسیون است. این را با رگرسیون خطی (Linear Regression) نباید اشتباه گرفت، رگرسیون خطی تنها یکی از الگوریتمهای نظارتشده برای حل مسائل رگرسیون است ولی الگوریتمهای متنوع دیگری هم در این حوزه وجود دارند.
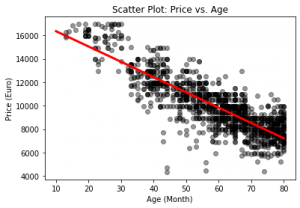
برای نمونه، شکل-۱ نمودار پراکندگی (Scatter Plot) قیمت خودروهای دستدوم برحسب عمر خودرو را نشان میدهد. تصویر حکایت از این دارد که هرچه عمر خودرو افزایش پیدا کند، قیمت آن کاهش مییابد. در این مسئله متغیر پاسخ (قیمت خودرو) از جنس متغیر پیوسته است، بنابراین با یک مسئله رگرسیون مواجه هستیم.

در شکل-۲، من با استفاده از الگوریتم رگرسیون خطی، رابطه بین قیمت خودروهای دستدوم و عمر خودرو را با استفاده از الگوریتم رگرسیون خطی برآورد کردم و با خط قرمز روی نمودار پراکندگی انداختم. از روی این خط میتوان به برآوردی از قیمت خودرو رسید. برای مثال، از شکل پیدا است اگر عمر خودرو ۶۰ ماه باشد، پیشبینی از قیمت خودرو، نزدیک ۱۰ هزار یورو است.
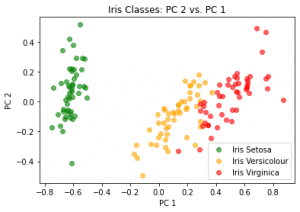
وقتی هدف از مسئله نظارتشده، پیشبینی یک متغیر رستهای (Categorical Variable) باشد، مسئله از نوع دستهبندی است. برای نمونه، در گیاهشناسی زنبق به سه دسته اصلی تقسیم میشود: Setosa، Versicolour و Virginic. شکل-۳، دادههای مربوط به پراکندگی این سه دسته زنبق را بر اساس طول و عرض کاسبرگ گلهایشان نشان میدهد.
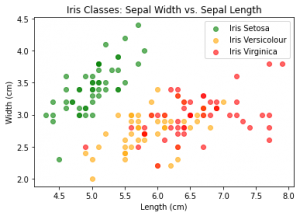
در این مثال، هدف آن است که بر اساس طول و عرض کاسبرگ، دستهای که زنبق به آن تعلق دارد پیشبینی شود. متغیر پاسخ در این مثال، یک متغیر رستهای است، بنابراین مسئله از نوع دستهبندی است. در شکل-۴، من با استفاده از یکی از الگوریتمهای دستهبندی، معروف به تحلیل تفکیککننده خطی (Linear Discriminant Analysis – LDA) این مسئله را حل کردم.
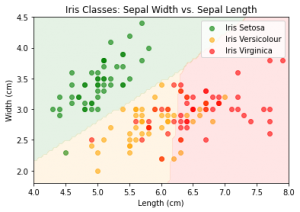
در شکل بالا مشخص است، بسته به اینکه طول و عرض کاسبرگ چقدر باشد، فضای مختصات به سه رنگ که معرف سه دسته گیاه زنبق است، تقسیم میشود. برای مثال اگر گیاه زنبقی دارای طول کاسبرگ پنج سانتیمتر و عرض کاسبرگ ۳٫۵ سانتیمتر باشد، در ناحیه سبزرنگ میافتد و پیشبینی الگوریتم آن است که چنین زنبقی به خانواده Setosa تعلق دارد.
همانطور که در شکل-۴ پیداست، الگوریتم دسته همه مشاهدات را بهدرستی پیشبینی نکرده است. برای مثال در گوشه پایین سمت چپ تصویر، مشاهدهای وجود دارد که سبزرنگ است ولی در ناحیه زرد قرار گفته است. خوبی مسائل نظارتشده آن است که چون مقدار واقعی متغیر پاسخ مشاهدات مشخص است میتوان آن را با مقدار پیشبینیشده مقایسه کرد و به ارزیابی از کیفیت مدل یادگیری ماشین رسید.
برآورد اینکه یک غده سرطانی خوشخیم است یا بدخیم، پیشبینی اینکه متقاضی وام یک بانک، میتواند در آینده بهطور کامل وام را بازپرداخت کند یا نه و تشخیص اینکه ایمیل جدیدی که به صندوق پست الکترونیکی شما آمده، سالم است یا حاوی محتوای تبلیغاتی زرد (Spam) مثالهای از کاربردهای الگوریتمهای دستهبندی در دنیای واقعی است.
بسیاری از الگوریتمهای دستهبندی بهجای آنکه مستقیم دسته مشاهده را پیشبینی کند، احتمال آن را که یک مشاهده به هر دسته تعلق داشته باشد، پیشبینی میکند. برای مثال، ممکن است خروجی یک الگوریتم دستهبندی این باشد که بیمار مبتلا به غده سرطانی با احتمال ۲۰ درصد غده بدخیم دارد و با احتمال ۸۰ درصد غده خوشخیم دارد. البته درنهایت از منظر کاربردی ما نیاز داریم که رسته مشاهده را مشخص کنیم. در این صورت، رستهای که بالاترین احتمال را دارد، بهعنوان پیشبینی نهایی اعلام میشود.
باید توجه کرد که الگوریتمهایی را که برای حل مسائل رگرسیون استفاده میشوند، نمیتوان به همان شکل برای حل مسائل دستهبندی بکار برد و برعکس. گرچه برخی از الگوریتمهای یادگیری ماشین هستند که با تغییراتی برای حل هر دو نوع مسئله بکار میروند.
یادگیری نظارتنشده
در یادگیری نظارتنشده، متغیر پاسخی وجود ندارد که بر فرآیند یادگیری نظارت کند و الگوریتم مستقیماً روی ویژگیها پیادهسازی میشود. هدف از یادگیری نظارتشده فهم بهتر دادهها و کشف الگوهای پنهان است. بهطور خلاصه میتوان گفت یادگیری نظارتنشده به دنبال پیدا کردن گروهها در دادهها است. اگر این گروهها روی مشاهدات باشند، مسئله خوشهبندی (Clustering) است و اگر این گروهها روی ویژگیها پیدا شوند، مسئله از جنس کاهش بُعد (Dimension Reduction) است. البته انگیزه این دو نوع مسئله کاملاً متفاوت است.
هدف از خوشهبندی تقسیم کردن مشاهدات بر اساس ویژگیها به گروههایی است که در داخل هر گروه مشاهدات کمابیش شبیه به هم هستند. برای مثال، خوشهبندی مشتریان از منظر رفتار خرید به این معنی است که آنان را به گروههایی بخشبندی کنیم که داخل هر گروه مشتریان نسبتاً همگن هستند و رفتار خرید مشابهی دارند.
من یکی از الگوریتمهای معروف خوشهبندی، یعنی الگوریتم K-means را روی شکل-۵ بکار بردم و نتیجه را در شکل-۶ میتوانید ببینید. در شکل-۶ پیدا است تصویر اصلی بر اساس، رنگ پیکسلها به پنج خوشه تقسیم شده و نواحی که ازنظر رنگ شبیه یکدیگر بودند در یک گروه افتادهاند.


در سمت دیگر، الگوریتمهای کاهش بُعد به دنبال این هستند که تعداد متغیرها را کم کنند و معمولاً در مراحل آمادهسازی داده (Data Preparation) از آنان استفاده میکنند. علت علاقهمندی به کاهش بُعد این است که افزایش تعداد متغیر پیشبینی کننده از یک حدی بیشتر در عملکرد الگوریتمهای یادگیری ماشین اثر منفی میگذارد.
برای مثال، وجود تعداد زیادی متغیر پیشبینی کننده در رگرسیون خطی اغلب با پدیدهای تحت عنوان همخطی (Multi-collinearity) همراه است، به این معنی که متغیرهای پیشبینی کننده خودشان دارای همبستگی بالا با یکدیگر میشوند که غیرقابلاعتماد شدن نتایج آزمون t و بازه اطمینان ضرایب رگرسیون خطی را در پی دارد. به همین خاطر ممکن است ما علاقهمند باشیم که تعداد متغیرها را کاهش دهیم.
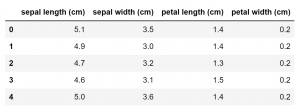
در مثال دستهبندی گیاهان زنبق، دادههای اصلی شامل چهار متغیر هستند: طول کاسبرگ، عرض کاسبرگ، طول گلبرگ و عرض گلبرگ (شکل-۷).
من بر روی این دادهها یک الگوریتم کاهش بُعد بنام تحلیل مؤلفه اصلی (Principal Component Analysis – PCA) را پیادهسازی کردم و به دو متغیر جدید تحت عنوان مؤلفه اصلی اول (PC 1) و مؤلفه اصل دوم (PC 2) رسیدم. سپس در فضای این متغیرهای جدید، دادهها را به نمایش درآوردهام (شکل-۸). با این کار، بهجای آنکه از چهار متغیر اولیه برای توصیف دادهها استفاده کنم، از دو متغیر جدید استفاده کردم. بهاینترتیب تعداد متغیرهای مسئله کمتر شده است. این متغیرهای جدید ممکن است بهعنوان متغیرهای پیشبینی کننده برای حل مسئله دستهبندی گیاهان زنبق استفاده شوند.
یک چالش مهم در مسائل نظارتنشده، ارزیابی کیفیت مدل است. در الگوریتمهای نظارتشده هدف تحلیل پیشبینی متغیر پاسخ است. به همین دلیل شما بهراحتی میتوانید خطای مدل را سنجش کنید. درحالیکه در الگوریتمهای نظارتنشده متغیر پاسخی وجود ندارد و ما پاسخ درست را نمیدانیم که بتوانیم خروجی مدل را با آن مقایسه کنیم.
یادگیری تقویتی
یادگیری تقویتی نسل دیگری از الگوریتمهای یادگیری ماشین است که اخیراً موردتوجه زیادی قرار گرفته است. برای آنکه این رویکرد را توضیح دهم، به یکی از مسائل معروف حوزه یادگیری تقویتی اشاره میکنم. در این مسئله که به آونگ وارون (Inverted Pendulum) معروف است، ارابهای وجود دارد که یک آونگ به آن متصل است (شکل-۹). مرکز جرم آونگ بالای نقطه چرخش آن قرار دارد. آونگ از حالت عمودی به شکل وارونه رها میشود و هدف آن است که با تکان دادن ارابه به سمت چپ و راست، آونگ را به شکل وارونه در حال تعادل قرار داد.

حسگرهایی که به این سیستم متصل هستند در هرلحظه موقعیت ارابه روی محور افقی، سرعت ارابه، زاویه آونگ و سرعت زاویهای آونگ را ثبت میکنند. در ویدئو زیر میبینید که من مسئله آونگ وارون را در پایتون شبیهسازی کردم و بهصورت کاملاً تصادفی با حرکات چپ و راست ارابه را هدایت میکنم. البته واضح است که با حرکات تصادفی نمیتوان آونگ را به حالت تعادل درآورد.
چطور یادگیری ماشین میتواند برای حل چنین مسئلهای بکار رود؟ برای درک شهودی از نحوه آموزش ماشین در چنین مسئلهای، به این فکر کنید اولین بار چطور دوچرخهسواری یاد گرفتید. بیشتر ما با سعی و خطا کردن و افتادن و دوباره بلند شدن یاد گرفتیم که چطور تعادلمان را روی دوچرخه حفظ و درنهایت بتوانیم با آن حرکت کنیم. یادگیری تقویتی هم از چنین رویکردی استفاده میکند.
برخلاف مثال پیشبینی قیمت خودروهای دستدوم که دادهها از قبل گردآوری و سپس وارد الگوریتم میشوند برای حل چنین مسئلهای از قبل دادهای وجود ندارد، بلکه داده از طریق اجرا کردن و سعی و خطا به دست میآید. در مثال آونگ وارون، هوش مصنوعی ابتدا نمیداند که با توجه به موقعیت آونگ باید ارابه را به کدام جهت حرکت دهد تا بتواند تعادل آن را حفظ کند. پس با یک سری حرکات تصادفی شروع میکند. طبیعی است که با این حرکات تصادفی نمیتواند تعادل آونگ را حفظ کند، ولی برخی از آنها ممکن است موجب شوند در مدت کوتاهی آونگ را متعادل نگهدارند.
برای آنکه هوش مصنوعی متوجه شود کدامیک از این حرکات تصادفی خوب بوده باید یک مکانیزم بازخورد تعریف کرد که وقتی هوش مصنوعی کارهایی انجام میدهد که در جهت رسیدن به هدف است، پاداش دریافت کند. پاداش اقدامات درست را در جهت رسیدن به هدف تقویت میکند.
بهاینترتیب هوش مصنوعی پس از سعی و خطا کردنهای زیاد بهتدریج یاد میگیرد که در هر موقعیت چه اقداماتی انجام دهد که منجر به حداکثر کردن پاداش شود. من مثال آونگ وارون را در پایتون، با استفاده از یکی از الگوریتمهای یادگیری تقویتی بنام Q-Learning حل کردم و نتیجه را در ویدئوی زیر نشان دادم. در این ویدئو هوش مصنوعی پس از ۲۰۰ بار تلاش، بهتدریج یاد میگیرد چگونه با چپ و راست کردن ارابه، آونگ را مستقیم نگه دارد.
جمعبندی
همانطور که اشاره کردم یادگیری ماشین شاخهای از هوش مصنوعی است که به دنبال استدلال کردن و تصمیمگیری بر اساس دادههاست. مسائل یادگیری ماشین به سه دسته کلی تقسیم میشوند: مسائل یادگیری نظارتشده، یادگیری نظارتنشده و یادگیری تقویتی.
در مسائل یادگیری نظارتشده متغیر پاسخ وجود دارد و هدف پیشبینی آن است. در یادگیری نظارتنشده متغیر پاسخی وجود ندارد و الگوریتم مستقیماً روی ویژگیها پیادهسازی میشود و هدف کشف ساختارهای پنهان در دادههاست. یادگیری تقویتی معمولاً برای حل مسائلی بکار میرود که تنها راه جمعآوری داده تعامل با محیط و اقدام کردن است و با ایجاد مکانیزم پاداش، ماشین بهتدریج یاد میگیرد در جهت رسیدن به هدف چه اقداماتی انجام دهد.
برای پیوند زدن مطالب این مقاله به دنیای کاربردی، به شما توصیه میکنم در هر یک از مسائل زیر حدس بزنید کدام رویکرد یادگیری ماشین مناسبتر است:
پیدا کردن گروههایی از مشتریان که حساسیت مشابهی نسبت به قیمت دارند،
پیشبینی قیمت خانه بر اساس سال ساخت، متراژ، مکان جغرافیایی و …،
آمادهسازی یک دیتاست با ۲۰۰ متغیر برای تحلیل رگرسیون،
پیشبینی بازده یک سهام در ماه آتی،
محاسبه احتمال آنکه یک تراکنش بانکی متقلبانه است،
رباتی که در نقش خدمات مشتریان با آنان چت میکند، و
طراحی سامانهای که به مشتریان یک پلتفورم خردهفروشی آنلاین، محصولات پیشنهاد میدهد.
منابع
Boehmke, B., & Greenwell, B. (2019). “Hands-on Machine Learning with R”, Chapman and Hall/CRC
Hao, K. (2018). “What Is Machine Learning”, MIT Technology Review, https://www.technologyreview.com/2018/11/17/103781/what-is-machine-learning-we-drew-you-another-flowchart/