در این مقاله به موضوعات مقدماتی شامل نحوه تخصیص یک متغیر، کار با بردارها، ماتریسها و قالبهای داده و همچنین توابع پایهای و پرکاربرد ریاضی و آماری میپردازم. رویکرد من در آموزش زبان برنامهنویسی R بیشتر مبتنی بر استفاده از مثال است تا خواننده با اجرای کدها بتواند این زبان را یاد بگیرد.
اگر R را بر روی سیستم خود نصب و آن را اجرا کنید، پنجرهای مانند شکل-۱ ظاهر میشود. در این پنجره شما قادر هستید که به کدنویسی بپردازید.
قبل از پرداختن به کدنویسی توجه کنید که زبان R نسبت به بزرگ و یا کوچک بودن حروف حساس است.
نشانی فضای کاری (Work Directory)
همیشه بهتر است در ابتدا نشانی فضای کاری را مشخص کنید. این نشانی جایی در کامپیوتر شماست که R همه فایلها را از آنجا میخواند و یا اگر فایلی را بخواهد بنویسد در این نشانی ذخیره میکند. برای فهمیدن این نشانی از تابع getwd استفاده میشود. اگر این تابع را وارد و سپس آن را اجرا کنید، نشانی فضای کاری R مشخص میشود. توجه کنید خروجی این تابع روی کامپیوتر شما چیز دیگری خواهد بود.
1 2 | > getwd() [1] "C:/Users/FarzadM/Documents" |
اگر بخواهید این نشانی را به آدرس دیگری تغییر دهید از تابع setwd به شکل زیر استفاده کنید. نشانیِ داخلِ تابع جایی است که میخواهیم فضای کاری جدید قرار گیرد. به نحوه آدرسدهی حتماً توجه کنید. اگر دوباره از تابع getwd استفاده کنید، مشاهده میکنید نشانی فضای کاری تغییر کرده است.
1 2 3 | > setwd("C:/Users/FarzadM/Desktop") > getwd() [1] "C:/Users/FarzadM/Desktop" |
تخصیص ورودی (Entering Input)
برای تخصیص یک عبارت به یک متغیر از نماد -> استفاده میشود (میتوان از علامت = نیز استفاده کرد). در مثال زیر عدد ۱۰ به متغیر x تخصیص داده شده است. اگر بخواهید x را فراخوانی کنید بهراحتی میتوانید آن را تایپ کرده و Enter را فشار دهید یا از تابع print به ترتیب زیر استفاده کنید. همچنین در زیر کلمه hello به متغیر txt تخصیص داده شده است.
1 2 3 4 5 6 7 8 | > x<- 10 > x [1] 10 > print(x) [1] 10 > txt <- "hello" > txt [1] "hello" |
در بالا وقتی x را فراخوانی میکنید، [۱] نشان میدهد که x یک بردار است که اولین مؤلفه آن ۱۰ است. البته در اینجا x تنها یک مؤلفه دارد.
برای اینکه کدهایمان خواناتر و گویاتر شود، ممکن است برای یادآوری بخواهیم جلوی هر کد عبارات و نکاتی را بنویسم تا برای خودمان و یا دیگران مشخص کنیم که آن بخش از کد با چه هدفی نوشته شده است. برای این منظور، در ابتدای کد از علامت # استفاده میکنیم. این علامت به R یادآوری میکند که لازم نیست آن قسمت را اجرا کند.
انواع شیء (Object) در R
تمام چیزهایی که در R با آنها سروکار داریم شیء نامیده میشوند. درواقع شیء مانند اتم میماند؛ کوچکترین جزء تشکیلدهنده R است. پنج کلاس اصلی آن به ترتیب زیر است:
کاراکتر (Character) به هر نشانهای گفته میشود که مورد پردازش متنی قرار میگیرد مانند a ،B ،۲ و غیره.
اعداد حقیقی (Numeric)
اعداد صحیح (Integer)
اعداد موهوم (Complex)
خروجی منطقی (Logical) که دلالت بر درستی یا نادرستی یک گزاره دارند.
یکی از پایهایترین اشیاء در R بردار (Vector) است. بردارها در بیشتر موارد شامل اشیائی از یک کلاس هستند.
اغلب اعداد به شکل اعداد حقیقی در R ذخیره میشوند. حتی وقتی شما عددی مانند ۲ را میبینید، در پشت پرده این عدد به شکل یک عدد حقیقی ذخیرهشده است. این امکان وجود دارد که آن را به شکل صریح در کلاس اعداد صحیح قرار دهید و یا آن را به شکل کاراکتر تعریف کنید. اگر یک عدد را به شکل کاراکتر تعریف کنیم، آنگاه نمیتوان محاسبات ریاضی روی آن انجام داد.
در کد زیر، ابتدا عدد ۲ را به متغیر x تخصیص دادم، با تابع class، کلاس آن را فراخوانی کردم و سپس آن را با تابع as.character به کاراکتر برگرداندم. دقت کنید وقتی x به شکل کاراکتر برگردانده شده است، خروجی آن در داخل گیومه به نمایش درمیآید. حال اگر x را در یک محاسبه ریاضی مانند جمع بکار ببرم، پیام خطا دریافت میکنم. با استفاده از تابع as.numeric دوباره میتوان x را به کلاس اعداد حقیقی تبدیل کرد.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | > x <- 2 > class(2) [1] "numeric" > x <- as.character(x) > x [1] "2" > class(x) [1] "character" > x + 2 Error in x + 2 : non-numeric argument to binary operator > x <- as.numeric(x) > class(x) [1] "numeric" > x [1] 2 |
ساختارهای داده (Data Structures)
در زبان R میتوان دادهها را به روشهای مختلف سازماندهی کرد. من در ادامه مقاله به روشهای متداول زیر اشاره میکنم:
بردارها (Vectors)
ماتریسها (Matrices)
لیستها (Lists)
قالبهای داده (Data Frames)
بردارها
از تابع c میتوان برای ساخت برداری از اشیاء استفاده کرد. به مثالهای زیر توجه کنید:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | > d1 <- c(1,2,3,4,5) > d1 [1] 1 2 3 4 5 > d2 <- c(6,7,8) > d2 [1] 6 7 8 > d3 <- c(d1,d2) > d3 [1] 1 2 3 4 5 6 7 8 > d4 <- c("Ali", "Babak", "Sara") > d4 [1] "Ali" "Babak" "Sara" > d5 <- c(TRUE,FALSE) > d5 [1] TRUE FALSE |
توجه کنید که بردار d3 از ترکیب دو بردار d1 و d2 به دست آمده و مؤلفههای بردار d5 از کلاس منطقی هستند. روشهای دیگری نیز وجود دارد که میتوان با آن بردار ایجاد کرد. برای نمونه در زیر برای تخصیص اعداد طبیعی از ۱ تا ۱۰ به بردار d6 از عملگر : استفاده کردم:
1 2 3 | > d6 <- 1:10 > d6 [1] 1 2 3 4 5 6 7 8 9 10 |
اگر بخواهید سری اعداد ۱ تا ۱۰ را (شروع از ۱) بافاصله دوتادوتا وارد کنید، از کد زیر باید استفاده کرد:
1 2 3 | > d7 <- seq(1,10,by=2) > d7 [1] 1 3 5 7 9 |
اگر بخواهید از بین سری اعداد ۱ تا ۱۰ (شروع از ۱) یک بردار با چهار مؤلفه انتخاب کنید که فاصله آنها از یکدیگر برابر باشد، از کد زیر باید استفاده کرد:
1 2 3 | > d8 <- seq(1,10,length = 4) > d8 [1] 1 4 7 10 |
اگر طول این بردار بخواهد ۵ باشد، به شکل زیر عمل میکنیم:
1 2 3 | > d8 <- seq(1,10, length=5) > d8 [1] 1.00 3.25 5.50 7.75 10.00 |
اگر بخواهیم یک بردار از مجموعه اعداد تکراری ایجاد کنیم، از تابع rep استفاده میکنیم:
1 2 3 4 | > rep(1,5) [1] 1 1 1 1 1 > rep(1:3,5) [1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 |
همچنین اگر بخواهیم طول یک بردار را محاسبه کنیم از تابع length استفاده میکنیم:
1 2 | > length(d6) [1] 10 |
برای انتخاب دومین عنصر بردار d6 و انتخاب همزمان سومین و چهارمین عنصر بردار d6 از کدهای زیر استفاده کردم:
1 2 3 4 | > d6[2] [1] 2 > d6[c(3,4)] [1] 3 4 |
اگر بخواهیم عناصر یک بردار را به ترتیب بزرگ به کوچک یا برعکس مرتب کنیم میتوان از تابع sort استفاده کرد.
1 2 | > sort(d6, decreasing = TRUE) [1] 10 9 8 7 6 5 4 3 2 1 |
در کد بالا توجه کنید چون decreasing = TRUE قرار گرفته است، مقادیر از بزرگ به کوچک مرتب شدهاند، در غیراینصورت مقادیر از کوچک به بزرگ مرتب میشدند.
برخی از توابع ریاضی پایه (Basic Math Functions)
در این جا تنها به برخی از توابع پرکاربرد ریاضی اشاره میکنم.
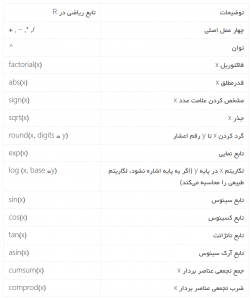
به مثالهای زیر که کاربرد توابع بالا را نشان میدهد توجه کنید:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | > x = -23.45671 > y = 5.143089 > abs(x) [1] 23.45671 > sign(x) [1] -1 > sign(y) [1] 1 > sqrt(25) [1] 5 > round(x,3) [1] -23.457 > exp(0) [1] 1 > log(100,10) [1] 2 > log(exp(1)^5) [1] 5 > sin(2*pi) [1] -2.449213e-16 > cumsum(1:5) [1] 1 3 6 10 15 > cumprod(1:5) [1] 1 2 6 24 120 > factorial(5) [1] 120 |
توابع آماری پایه (Basic Statistical Functions)
توابع پرکاربرد آماری در R را نیز در جدول زیر خلاصه کردم:

مثالهای زیر کاربرد توابع بالا را نشان میدهد:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | > v1 <- c(1,4,5,7,9,13) > v2 <- c(10,37, 53, 68, 81, 118) > min(v1) [1] 1 > max(v1) [1] 13 > mean(v1) [1] 6.5 > var(v1) [1] 17.5 > sd(v1) [1] 4.1833 > cor(v1,v2) [1] 0.9965388 |
توابع منطقی پایه (Logical Functions)
در کد زیر ابتدا یک بردار تعریف کردم تا کاربرد توابع منطقی را نشان دهم.
اولین عبارت منطقی نشان می دهد آیا هر کدام از عناصر بردار مساوی عدد ۶ است یا خیر.
دومین عبارت بیان می کند چندمین عنصر مساوی عدد ۶ است.
سومین عبارت سوال می کند آیا عنصری در بردار مذکور، بزرگتر از عدد ۷ است یا خیر.
چهارمین عبارت بررسی می کند آیا همه عناصر بردار از ۷ کوچکتر مساوی هستند یا خیر.
علامت ! در R نشان دهنده نقیض یک گزینه است. پنجمین عبارت نقیض عبارت اول است.
& نشان دهنده “و” (AND) و | نشان دهنده “یا” (OR) است. آخرین عبارت می گوید آیا اعضایی در بردار وجود دارند که از ۷ بزرگتر باشند و کوچکتر مساوی ۱۰ باشند.
1 2 3 4 5 6 7 8 9 10 11 12 13 | > v1<- c(1,4,6,7,9,13) > v1 == 6 [1] FALSE FALSE TRUE FALSE FALSE FALSE > which (v1 == 6) [1] 3 > any(v1 > 7) [1] TRUE > all(v1 <= 7) [1] FALSE > ! v1 ==6 [1] TRUE TRUE FALSE TRUE TRUE TRUE > any(v1 > 7) & any(v1 <= 10) [1] TRUE |
ماتریسها
ماتریسها آرایهای از اعداد هستند که دارای دو بعد (سطر و ستون) هستند. برای نشان دادن نحوه کار با ماتریسها در R فرض کنید ماتریس A به شکل زیر تعریف شده است:
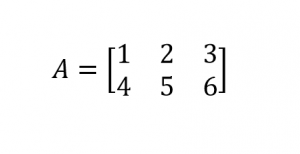
برای تعریف ماتریس A از تابع matrix به شکل زیر استفاده میکنم:
1 2 3 4 5 | > A = matrix(c(1:6), nrow = 2, ncol = 3, byrow = TRUE ) > A [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6 |
در کد بالا ابتدا، بردار درایه یا عناصر ماتریس را تعریف کردم به شکلی که در دو سطر (nrow=2) و سه ستون (ncol=3) جای بگیرند. درنهایت گفته شده است که اعداد بردار مذکور سطر به سطر در ماتریس جای بگیرند. اگر بخواهیم اعداد را ستون به ستون در ماتریس جای دهیم، در انتها باید عبارت byrow = FALSE قرار داده میشد.
ابعاد یک ماتریس (تعداد سطر و ستون) را با استفاده از تابع dim به دست میآوریم.
1 2 | > dim(A) [1] 2 3 |
فراخوانی درایههای ماتریس
اگر بخواهم درایه واقع در سطر اول و ستون سوم را فراخوانی کنم از کد زیر استفاده میکنم:
1 2 | > A[1,3] [1] 3 |
اگر بخواهم تمام درایههای سطر اول و یا تمام درایههای ستون دو را فراخوانی کنم، به ترتیب زیر عمل میکنم:
1 2 3 4 | > A[1,] [1] 1 2 3 > A[,2] [1] 2 5 |
این امکان وجود دارد که برای مثال درایههای بیش از یک ستون را فراخوانی کنم:
1 2 3 4 | > A[,c(2,3)] [,1] [,2] [1,] 2 3 [2,] 5 6 |
میتوان همه درایههای ماتریس بهجز ستون اول را به شکل زیر انتخاب کرد:
1 2 3 4 | > A[,-1] [,1] [,2] [1,] 2 3 [2,] 5 6 |
در کد زیر تنها درایههایی را انتخاب کردم که مقدار عددی آنها از ۴ بزرگتر است:
1 2 | > A[A > 4] [1] 5 6 |
اگر به دنبال درایههایی باشم که بر دو بخشپذیر هستند (اعداد زوج) از کد زیر استفاده میکنم:
1 2 | > A[A%%2 == 0] [1] 4 2 6 |
توجه کنید در کد بالا، عملگر %% باقیمانده عدد سمت چپ را در تقسیم آن بر عدد سمت راست محاسبه میکند.
نامگذاری سطرها و ستونهای ماتریس
همچنین میتوانیم به سطرها و ستونهای ماتریس اسم دلخواه اختصاص دهیم و درایههای ماتریس را با اسمشان هم فراخوانی کنیم:
1 2 3 4 5 6 7 | > dimnames(A) = list(c("r1","r2"),c("c1","c2","c3")) > A c1 c2 c3 r1 1 2 3 r2 4 5 6 > A["r1","c2"] [1] 2 |
با استفاده از توابع rownames و colnames میتوانید به ترتیب سطرها و ستونهای یک ماتریس را نامگذاری کنید.
1 2 3 4 5 6 | > rownames(A) <- c("r1","r2") > colnames(A) <- c("c1","c2","c3") > A c1 c2 c3 r1 1 2 3 r2 4 5 6 |
ترانهاده ماتریس
برای به دست آوردن ترانهاده ماتریس A از تابع t استفاده میشود. جهت یادآوری ترانهاده یک ماتریس، از جابجا کردن سطرها و ستونهای آن به دست میآید.
1 2 3 4 5 | > t(A) [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 |
ترکیب ماتریسها
اگر بخواهیم دو ماتریس را به شکل ستونی با یکدیگر ترکیب کنیم از تابع cbind استفاده میکنیم. بهطور مشابه اگر بخواهیم دو ماتریس را به شکلی سطری ترکیب کنیم از تابع rbind بهره میبریم.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | > B = matrix(c(7,8,9,10), nrow = 2, ncol = 2, byrow = T) > B [,1] [,2] [1,] 7 8 [2,] 9 10 > cbind(A,B) [,1] [,2] [,3] [,4] [,5] [1,] 1 2 3 7 8 [2,] 4 5 6 9 10 > rbind(t(A),B) [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 [4,] 7 8 [5,] 9 10 |
اصلاح درایههای ماتریس
از دستوراتی که در بالا برای فراخوانی درایههای ماتریس استفاده کردم، میتوان برای اصلاح درایههای آنهم استفاده کرد.
برای مثال در کد زیر درایه واقع در سطر اول و ستون سوم، به عدد ۱۰ تغییر یافته است:
1 2 3 4 5 | > A[1,3] <- 10 > A [,1] [,2] [,3] [1,] 1 2 10 [2,] 4 5 6 |
یا در کد زیر همه درایههای ماتریس اولیه A که مقداری کمتر از ۴ دارند، صفر شدهاند:
1 2 3 4 5 | > A[A < 4] <- 0 > A [,1] [,2] [,3] [1,] 0 0 0 [2,] 4 5 6 |
در مثال زیر به همه درایههای ماتریس اولیه، ۵ واحد اضافه شده است:
1 2 3 4 | > A + 5 [,1] [,2] [,3] [1,] 6 7 8 [2,] 9 10 11 |
ابعاد یک ماتریس را هم میتوان تغییر داد. برای مثال به کد زیر توجه کنید:
1 2 3 4 5 6 7 8 9 10 | > A [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6 > dim(A) <- c(3,2) > A [,1] [,2] [1,] 1 5 [2,] 4 3 [3,] 2 6 |
همچنین با استفاده از تابع c میتوان دوباره درایههای ماتریس را به شکل بردار درآورد:
1 2 3 4 | > c(A) [1] 1 4 2 5 3 6 > c(B) [1] 7 9 8 10 |
دترمینان ماتریس
برای محاسبه دترمینان یک ماتریس مربعی (دارای سطرها و ستونهای برابر) از تابع det استفاده میکنیم.
1 2 | > det(B) [1] -2 |
لیستها
فهرستها نوع خاصی از بردارها هستند که عناصر آن میتوانند کلاسهای مختلفی را در خود جای دهند. برای ساخت یک لیست از تابع list استفاده میشود. در مثال زیر میبینید که آخرین عضو در لیست، یک بردار است.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | > l <- list(1,"a", TRUE, 1+4i,c(1,2,3)) > l [[1]] [1] 1 [[2]] [1] "a" [[3]] [1] TRUE [[4]] [1] 1+4i [[5]] [1] 1 2 3 |
قالبهای داده
برای ذخیره دادههای جدولی در R از قالبهای داده یا دیتا فریم استفاده میشود. قالبهای داده کاربرد زیادی در مدلسازیهای آماری دارند. برای آنکه بهسادگی بتوانید آنها را درک کنید، وقتی به قالبهای داده فکر میکنید میتوانید یک جدول اکسل را تصور کنید. قالب داده را میتوان نوع خاصی از لیست در نظر گرفت که عناصر آن بردارهایی با طول یکسان هستند. به مثال زیر توجه کنید:
1 2 3 4 5 6 7 8 9 | > products <- c ("p1", "p2", "p3") > unitprice <- c(20,15,40) > monthlydemand <- c(1500, 2000, 850) > df <- data.frame(products,unitprice, monthlydemand) > df products unitprice monthlydemand 1 p1 20 1500 2 p2 15 2000 3 p3 40 850 |
همانطور که در بالا مشخص است برخلاف ماتریسها، قالبهای داده میتوانند کلاسهای مختلف را در خود جای دهند. درحالیکه درایههای یک ماتریس باید همگی از یک کلاس باشند.
زبان R دارای نمونههایی از دادههاست. یکی از این نمونهها mtcars نام دارد که به شکل دیتا فریم ذخیره شده است.
1 | > mtcars |
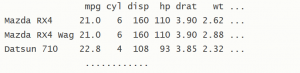
خط اول قالب داده سرتیتر (Header) خوانده میشود که حاوی اسامی ستونهاست. هر عضو قالب داده هم سلول نامیده میشود.
کار کردن با قالب داده از بسیاری جهات شبیه کار با ماتریسهاست. به مثالهای زیر توجه کنید:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 | > # Dimension > dim(mtcars) [1] 32 11 > nrow(mtcars) [1] 32 > ncol(mtcars) [1] 11 > # Header and Tail > head(mtcars) mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1 > tail(mtcars) mpg cyl disp hp drat wt qsec vs am gear carb Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.7 0 1 5 2 Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.9 1 1 5 2 Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.5 0 1 5 4 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.5 0 1 5 6 Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.6 0 1 5 8 Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.6 1 1 4 2 > # Extracting elments > mtcars[1,4] [1] 110 > mtcars["Mazda RX4", "hp"] [1] 110 > # Extracting columns > mtcars$mpg [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 [18] 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4 > mtcars[,"mpg"] [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 [18] 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4 > mtcars[,1:3] mpg cyl disp Mazda RX4 21.0 6 160.0 Mazda RX4 Wag 21.0 6 160.0 Datsun 710 22.8 4 108.0 Hornet 4 Drive 21.4 6 258.0 Hornet Sportabout 18.7 8 360.0 Valiant 18.1 6 225.0 Duster 360 14.3 8 360.0 Merc 240D 24.4 4 146.7 Merc 230 22.8 4 140.8 Merc 280 19.2 6 167.6 Merc 280C 17.8 6 167.6 Merc 450SE 16.4 8 275.8 Merc 450SL 17.3 8 275.8 Merc 450SLC 15.2 8 275.8 Cadillac Fleetwood 10.4 8 472.0 Lincoln Continental 10.4 8 460.0 Chrysler Imperial 14.7 8 440.0 Fiat 128 32.4 4 78.7 Honda Civic 30.4 4 75.7 Toyota Corolla 33.9 4 71.1 Toyota Corona 21.5 4 120.1 Dodge Challenger 15.5 8 318.0 AMC Javelin 15.2 8 304.0 Camaro Z28 13.3 8 350.0 Pontiac Firebird 19.2 8 400.0 Fiat X1-9 27.3 4 79.0 Porsche 914-2 26.0 4 120.3 Lotus Europa 30.4 4 95.1 Ford Pantera L 15.8 8 351.0 Ferrari Dino 19.7 6 145.0 Maserati Bora 15.0 8 301.0 Volvo 142E 21.4 4 121.0 > mtcars[,c("mpg","hp")] mpg hp Mazda RX4 21.0 110 Mazda RX4 Wag 21.0 110 Datsun 710 22.8 93 Hornet 4 Drive 21.4 110 Hornet Sportabout 18.7 175 Valiant 18.1 105 Duster 360 14.3 245 Merc 240D 24.4 62 Merc 230 22.8 95 Merc 280 19.2 123 Merc 280C 17.8 123 Merc 450SE 16.4 180 Merc 450SL 17.3 180 Merc 450SLC 15.2 180 Cadillac Fleetwood 10.4 205 Lincoln Continental 10.4 215 Chrysler Imperial 14.7 230 Fiat 128 32.4 66 Honda Civic 30.4 52 Toyota Corolla 33.9 65 Toyota Corona 21.5 97 Dodge Challenger 15.5 150 AMC Javelin 15.2 150 Camaro Z28 13.3 245 Pontiac Firebird 19.2 175 Fiat X1-9 27.3 66 Porsche 914-2 26.0 91 Lotus Europa 30.4 113 Ford Pantera L 15.8 264 Ferrari Dino 19.7 175 Maserati Bora 15.0 335 Volvo 142E 21.4 109 > # Extracting rows > mtcars[1,] mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4 > mtcars[c(1,5),] mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.62 16.46 0 1 4 4 Hornet Sportabout 18.7 8 360 175 3.15 3.44 17.02 0 0 3 2 > mtcars["Camaro Z28",] mpg cyl disp hp drat wt qsec vs am gear carb Camaro Z28 13.3 8 350 245 3.73 3.84 15.41 0 0 3 4 > #Logical indexing > mtcars[mtcars$am == 1,] mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2 |
آخرین مثال احتمالاً نیاز به توضیح بیشتری داشته باشد. در این مثال، هدف این بوده که تنها سطرهایی انتخاب شوند که مقدار متغیر ستون am در آنها ۱ باشد.
گام بعدی برای یادگیری R، نحوه خواندن و نوشتن دادهها و نحوه نصب بسته (Package) از کتابخانه R است. برای یادگیری این موضوعات به مقاله “آموزش زبان R برای علوم داده: خواندن و نوشتن دادهها” مراجعه کنید.
مقالات آموزش زبان R در آنالیکا
آموزش زبان R برای علوم داده: مباحث مقدماتی
آموزش زبان R برای علوم داده: خواندن و نوشتن دادهها
آموزش زبان R برای علوم داده: عبارات شرطی و حلقهها
سلام
خدا قوت
ممنون بایت دسته بندی خوبی که در این مقاله قرار دادید.
سلام. خسته نباشید…من حدود ۲۰ متغیر داردم و حدود ۲۰ میلیون OBSERVATION . و قصد دارم دل پانل دیتا لاجیت رگرس کنم .. نرم افزارR ظرفیت این حجم از داده ها رو داره؟
با سلام،
پاسخ کوتاه شما این است که بله میتوان با R دادههای بزرگ را مانند آنچه شما مثال زدید تحلیل کرد. چند نکته در این خصوص به ذهنم میرسد که شاید برایتان مفید باشد:
اول، قانون سرانگشتی این است که زبان R در حالت استاندارد میتواند بین ۱ میلیون تا ۱ میلیارد رکورد را بدون مشکل تجزیهوتحلیل کند. دادههای بزرگتر از این با الگوریتمهای MapReduce تحلیل میشوند که در اینجا هم میتوانید از ترکیب هادوپ (Hadoop) و R استفاده کنید.
دوم، توجه کنید تعداد رکوردها یک برآورد سرانگشتی از حجم دادهها به دست میدهد. مهم، بزرگترین شیئی است که در طول فرآیند تحلیل ایجاد میشود. ممکن است شما تنها ده هزار رکورد داشته باشید ولی ماتریس فاصله برای این ده هزار رکورد در یک الگوریتم خوشهبندی سلسله مراتبی دارای ۵۰ میلیون فاصله است. بنابراین در کار با دادههای بزرگ مهم است که از روشهایی استفاده کنید که ازنظر محاسباتی کارآمد باشد.
سوم، در بیشتر کاربردها شما لازم ندارید از همه دادهها استفاده کنید بلکه میتوانید از آن نمونهگیری کنید. برای پروژه شما شاید گرفتن یک نمونه ۱ تا ۲ میلیونی کفایت کند.
چهارم، R تمام اشیاء را در حافظه RAM ذخیره میکند. این برای تحلیل دادههای بزرگ مشکلساز میشود. یک استراتژی استفاده از ماشینهای با حافظه RAM بیشتر است. حالت دیگر این است که بستههایی (Packages) مانند ff، ffbase، filehash و bigmemory استفاده کنید که اشیاء را در هارددیسک ذخیره میکنند.
موفق باشید.
سلام
من متوجه شدم برای تغییر دادن کلاس یک داده به کاراکتر یا فاکتور میشه به جای as.charachter یا as.factor از charahter و factor استفاده کرد. اما در مورد تابع as.numeric این موضوع صادق نیست.
این توابع فرقشون چیه؟ چه دلیلی داره که نیاز باشه حتما as. رو هم بذاریم؟
سلام سپاس بی نهایت برای مطالب فوق العادتود
با سلام و خسته نباشید.میشه یه کد بهم معرفی کنید که داده های بارش یک بازه زمانی خاص مثلا سال های ۹۴-۸۷ رو برام توی نرم افزار Rتفکیک کنه . سپاسگزارمیشم پاسخگو باشید.با تشکر
سلام ..چطور باید دستور دو بردار که برهم عمود باشند رو بنویسم؟؟؟
خدا خیر دنیا و آخرت رو بهت بده…ممنون
سلام و خسته نباشید من یه سری داده دارم که میخوام اون ها رو نرمال سازی کنم متغیر x رو چطوری معرفی کنم که شامل همه ی داده ها باشه
سلام
عالیییییییییییییی بود
ممنون
با سلام و تشکر از مطالب مفید. من یک فایل حاوی یک ستون دیتا دارم که می خواهم آنها را از فایل اصلی که شامل همان آیدی ها هستند حذف کنم چه دستوری باید بنویسم؟